说明:由于图片过于多没有一一截图,还望大家见谅。
3、集群的 Oracle Grid Infrastructure 的安装:
所需的oracle软件如下:
o 适用于 Linux 的 Oracle Database 11g 第 2 版 Grid Infrastructure (11.2.0.1.0)
o 适用于 Linux 的 Oracle Database 11g 第 2 版 (11.2.0.1.0)
o Oracle Database 11g 第 2 版 Examples(可选)
安装用于 Linux 的 cvuqdisk 程序包
在两个 Oracle RAC 节点上安装操作系统程序包 cvuqdisk。如果没有 cvuqdisk,集群验证实用程序就无法发现共享磁盘,当运行(手动运行或在 Oracle Grid Infrastructure 安装结束时自动运行)集群验证实用程序时,您会收到这样的错误消息:“Package cvuqdisk not installed”。使用适用于您的硬件体系结构(例如,x86_64 或 i386)的 cvuqdisk RPM。
cvuqdisk RPM 包含在 Oracle Grid Infrastructure 安装介质上的 rpm 目录中。
3.1 安装cvuqdisk
设置环境变量 CVUQDISK_GRP,使其指向作为 cvuqdisk 的所有者所在的组(本文为 oinstall):
[root@OceanI ~]# CVUQDISK_GRP=oinstall; export CVUQDISK_GRP
[root@OceanV ~]# CVUQDISK_GRP=oinstall; export CVUQDISK_GRP
在保存 cvuqdisk RPM 的目录中,使用以下命令在两个 Oracle RAC 节点上安装 cvuqdisk 程序包:
[root@OceanI rpm]# pwd
/data/grid/rpm
[root@OceanI rpm]# rpm -ivh cvuqdisk-1.0.7-1.rpm
[root@OceanV rpm]# rpm -ivh cvuqdisk-1.0.7-1.rpm
使用 CVU 验证是否满足 Oracle 集群件要求
记住要作为 grid 用户在将要执行 Oracle 安装的节点 (racnode1) 上运行。此外,必须为 grid 用户配置通过用户等效性实现的 SSH 连通性。
在grid软件目录里运行以下命令:
[root@OceanI grid]#$./runcluvfy.sh stage -pre crsinst -n OceanI,OceanV -fixup -verbose
使用 CVU 验证硬件和操作系统设置
[root@OceanI grid]#./runcluvfy.sh stage -post hwos -n OceanI,OceanV -verbose
查看 CVU 报告。CVU 执行的所有其他检查的结果报告应该为“passed”,之后才能继续进行 Oracle Grid Infrastructure 的安装。
3.2、为集群安装 Oracle Grid Infrastructure:
su - grid
#./runInstaller
此处省略 N 张图 ........
当弹出执行脚本的时候一定要先 local node 然后再remote node 切记不可一味图块
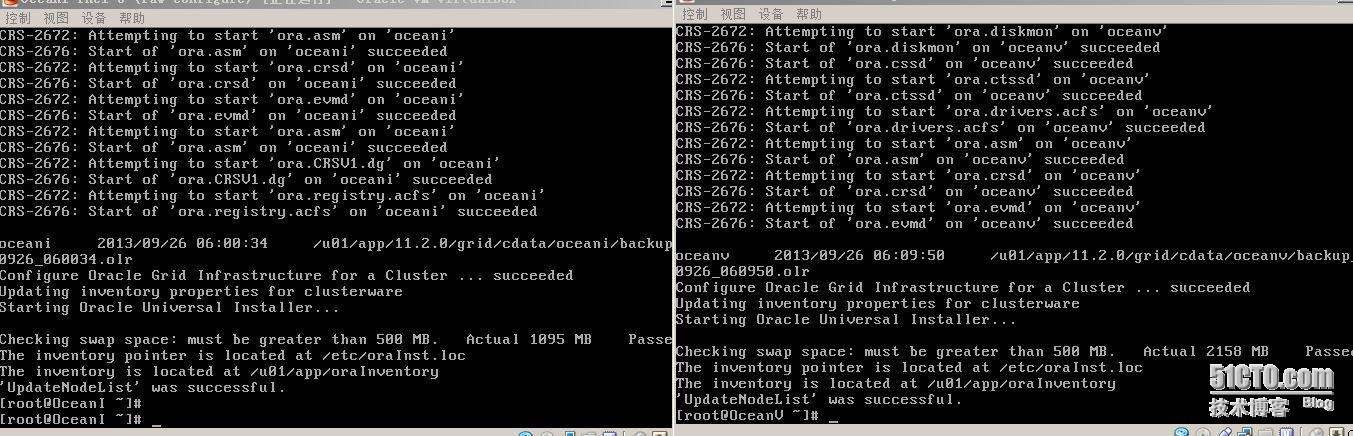
3.3、检验cluster安装是否成功
1.检查集群中的结点状态
2.检查SCAN是否产生,是否能ping通
3.检查所有服务的状态
4.检查ASM实例的状态
4、安装database soft & database
4.1、创建asm_group
su - grid
asmca
4.2、使用oracle用户调用图形界面进行安装Oracle Database
$./runInstaller
4.3、使用oracle用户调用dbca创建数据库
$dbca
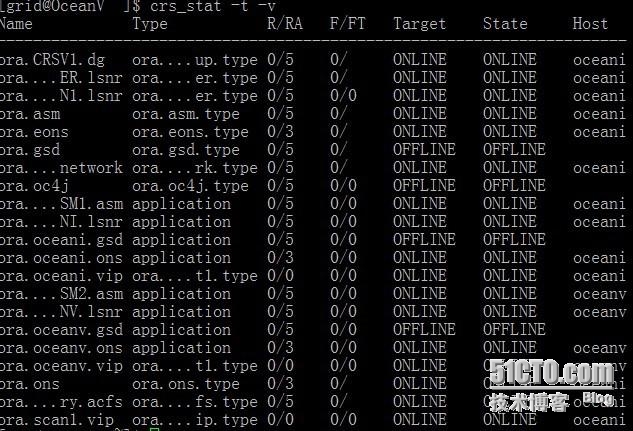
4.4、查看整个集群状态
#crs_stat -t
其它注意事项:
1.给votedisk和ocr创建ASM时,如果选择normal模式,则需要3个ASM disk。
2.安装Oracle Grid Infrastructure的ORACLE_HOME目录与ORACLE_BASE目录不能存在从属关系;而安装Oracle Database的ORACLE_HOME又必须在ORACLE_BASE目录下。
5、部分错误整理:
错误1:
在第一个节点执行root.sh时报错:
error while loading shared libraries:libcap.so.1:cannot open shared object file: No such file or directory
解决办法:
确定libcap包已经安装
rpm -q libcap
find / -name '*libcap*' -print
创建链接
ln -s /lib64/libcap.so.2.16 /lib64/libcap.so.1
删掉root.sh的配置:
./roothas.pl -deconfig -verbose -force
再次运行root.sh即可。
错误2:
这个错误会在Redhat6.x/CentOS6.x上安装Oracle11gR2 11.2.0.1 RAC时出现。
在第一个节点执行root.sh时报错(各个节点都会出现这个问题):
Adding daemon to inittab
CRS-4124: Oracle High Availability Services startup failed.
CRS-4000: Command Start failed, or completed with errors.
解决办法:(临时)
在生成了文件/var/tmp/.oracle/npohasd文件后,使用root立即执行以下命令命令:
/bin/dd if=/var/tmp/.oracle/npohasd of=/dev/null bs=1024 count=1
如果懒得看npohasd有没有生成,就用下面的命令让它自动完成
watch -n 0.5 /bin/dd if=/var/tmp/.oracle/npohasd of=/dev/null bs=1024 count=1
错误3:
通过dbca方式, 在基于ASM存储建库时, 报以下错误:
ORA-12547: TNS:lost contact
原因:
In environment where listener home (including SCAN listener which resides in Grid Infrastructure/ASM home) and database home are owned by different OS user, ORA-12537 could happen when connecting through listener, when creating database through DBCA, or when installing database software and creating a database in runInstaller. Job Role Separation is a typical example as SCAN and local grid home listener is owned differently than database.
解决办法:
检查grid安装的SCAN listener目录和Oracle Database目录的owner是不是一样的。如果不一样,改成一样或将目录设置为770权限。


