

License: Attribution-NonCommercial-ShareAlike 4.0 International
本文出自 Suzf Blog。 如未注明,均为 SUZF.NET 原创。
转载请注明:http://suzf.net/post/731
背景
在写压力负载比较重的MySQL实例上,InnoDB可能积累了较长的没有被purge掉的transaction history,导致实例性能的衰减,或者空闲空间被耗尽,下面就来看看它是怎么产生的,或者有没有什么方法来减轻,避免这样的问题出现。
InnoDB purge 概要
InnoDB是一个事务引擎,实现了MVCC特性,也就是在存储引擎里对行数据保存了多个版本。在对行数据进行delete或者update更改时,行数据的前映像会保留一段时间,直到可以被删除的时候。
在大部分OLTP负载情况下,前映像会在数据操作完成后的数秒钟内被删除掉,但在一些情况下,假设存在一些持续很长时间的事务需要看到数据的前映像,那么老版本的数据就会被保留相当长一段时间。
虽然MySQL 5.6版本增加了多个purge threads来加快完成老版本数据的清理工作,但在write-intensive workload情况下,不一定完全凑效。
测试案例
Peter Zaitsev 使用sysbench的update进行的测试,无论是 innodb_purge_threads=1 还是8的时候,显示的transaction history快速增长的情况,如下图所示:
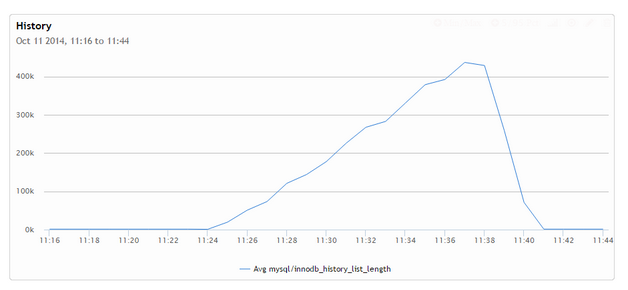
transaction history增长情况
下面看一下同步测试过程中purge的速度(可以通过I_S.innodb_metrics进行查询):
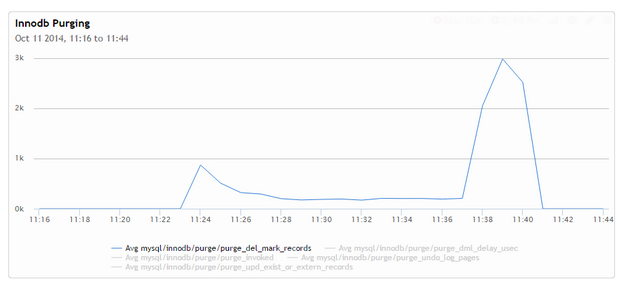
InnoDB purge 情况
显示在并发 process 的过程中,purge thread 其实处在饥饿状态,待sysbench结束,purge线程满载运行清理工作。
对于这个测试结果,这里需要说明下:
- 对于Peter Zaitsev的测试,其实主要是为了说明transaction history的情况,如果是用sysbench进行小事务的OLTP测试,并不会产生这么明显的transaction history增长而purge thread 跟不上的情况,或者他在测试的时候,对sbtest表进行了全表查询吧,或者设置了RR级别,不过这只是猜测。
- 对于undo page大部分被cache在buffer pool的情况下,purge thread还是比较快的,但如果因为buffer pool的不足而导致undo page被淘汰到disk上的情况,purge操作就会被受限IO情况, 而导致跟不上。
问题分析
我们来看下出现transaction history增长最常见的两种场景:
大查询
如果你在一张大表上发起一个长时间运行的查询,比如mysqldump,那么purge线程必须停下来等待查询结束,这个时候transaction undo就会累积。如果buffer pool中 free page紧张,undo page 还会被置换到disk上,加剧purge的代价。
MySQL重启
即使transaction history并没有急剧增加,但MySQL重启操作,buffer pool的重新预热,还是导致purge变成IO密集型操作。不过MySQL 5.6提供了InnoDB buffer pool的dump和reload方法,可以显著减轻purge的IO压力。
这里介绍一下如何查看buffer pool中undo page的cache情况,percona的版本上提供了I_S.innodb_rseg记录undo的分配和使用情况:
mysql> select sum(curr_size)*16/1024 undo_space_MB from innodb_rseg; +---------------+ | undo_space_MB | +---------------+ | 1688.4531 | +---------------+ 1 row in set (0.00 sec) mysql> select count(*) cnt, count(*)*16/1024 size_MB, page_type from innodb_buffer_page group by page_type; +--------+-----------+-------------------+ | cnt | size_MB | page_type | +--------+-----------+-------------------+ | 55 | 0.8594 | EXTENT_DESCRIPTOR | | 2 | 0.0313 | FILE_SPACE_HEADER | | 108 | 1.6875 | IBUF_BITMAP | | 17186 | 268.5313 | IBUF_INDEX | | 352671 | 5510.4844 | INDEX | | 69 | 1.0781 | INODE | | 128 | 2.0000 | SYSTEM | | 1 | 0.0156 | TRX_SYSTEM | | 6029 | 94.2031 | UNDO_LOG | | 16959 | 264.9844 | UNKNOWN | +--------+-----------+-------------------+ 10 rows in set (1.65 sec)
从这两个information_schema下的两张表可以看到:undo space使用的总大小是1.7G,而buffer pool中cached不足100M。
InnoDB 优化方法
在一定的写压力情况下,并发进行一些大查询,transaction history就会因为undo log无法purge而一直增加。
InnoDB提供了两个参数innodb_max_purge_lag,innodb_max_purge_lag_delay 来调整,即当trx_sys->rseg_history_len超过了设置的innodb_max_purge_lag,就影响DML操作最大delay不超过innodb_max_purge_lag_delay设置的时间,以microseconds来计算。
其核心计算代码如下:
/*******************************************************************//**
Calculate the DML delay required.
@return delay in microseconds or ULINT_MAX */
static
ulint
trx_purge_dml_delay(void)
/*=====================*/
{
/* Determine how much data manipulation language (DML) statements
need to be delayed in order to reduce the lagging of the purge
thread. */
ulint delay = 0; /* in microseconds; default: no delay */
/* If purge lag is set (ie. > 0) then calculate the new DML delay.
Note: we do a dirty read of the trx_sys_t data structure here,
without holding trx_sys->mutex. */
if (srv_max_purge_lag > 0) {
float ratio;
ratio = float(trx_sys->rseg_history_len) / srv_max_purge_lag;
if (ratio > 1.0) {
/* If the history list length exceeds the
srv_max_purge_lag, the data manipulation
statements are delayed by at least 5000
microseconds. */
delay = (ulint) ((ratio - .5) * 10000);
}
if (delay > srv_max_purge_lag_delay) {
delay = srv_max_purge_lag_delay;
}
MONITOR_SET(MONITOR_DML_PURGE_DELAY, delay);
}
return(delay);
}
但这两个参数设计有明显的两个缺陷:
缺陷1:针对total history length
假设transaction history中保留两类records,一类是是马上可以被purge的,一类是因为active transaction而不能purge的。但大多数时间,我们期望的是purgable history比较小,而不是整个history。
缺陷2:针对大小而非变化
trx_sys->rseg_history_len是一个当前history的长度,而不是一个interval时间段内undo的增长和减少的变化情况,导致trx_sys->rseg_history_len一旦超过innodb_max_purge_lag这个设定的值,就对DML产生不超过innodb_max_purge_lag_delay的时间delay,一旦低于这个值马上delay 时间就又恢复成 0。
在对系统的吞吐监控的时候,会发现系统抖动非常厉害,而不是一个平滑的曲线。类似于下图:

Purge 造成系统抖动
InnoDB purge 设计思路
针对InnoDB的purge功能,可以从以下几个因素来综合考虑:
- 增加默认 purge thread 的个数;
- 测量 purgable history 长度而不是总的长度;
- 针对变化进行调整 delay 数值,以应对 shrinking;
- 基于 undo space 的大小,而不是事务的个数;
- 调整 undo page 在 buffer pool 中的缓存策略,类似 insert buffer;
- 针对 undo page 使用和 index page 不同的预读策略。
以上6条可以针对purge线程进行一些改良。
当前调优方法
在当前的 MySQL 5.6 版本上,我们能做哪些调整或者调优方法,以减少transaction history增加带来的问题呢?
监控
监控trx_sys的innodb_history_list_length,为它设置报警值,及时关注和处理。
调整参数
如果你的实例是写压力比较大的话,调整innodb_purge_threads=8,增加并发purge线程数。
谨慎调整innodb_max_purge_lag和innodb_max_purge_lag_delay参数,依据现在的设计,可能你的实例的吞吐量会急剧的下降。
purge完之后再shutdown
大部分的case下,MySQL实例重启后,会发现purge的性能更差,因为undo page未命中的原因,并且是random IO请求。
如果是正常shutdown,就等purge完成再shutdown;如果是crash,就启动后等purge完成再接受业务请求。
预热
使用MySQL 5.6 提供的innodb_buffer_pool_dump_at_shutdown=on 和 innodb_buffer_pool_load_at_startup=on进行预热,把undo space page预热到buffer pool中。
原文出处:Taobao mysql
More: Taobao 数据内核月报
